


Hallucination
LLMs excel in language tasks yet are susceptible to 'AI hallucinations'—misinformation stemming from poor data and inadequate training. Here's what I've discovered.

Hello! Kevin Wang here. I'm a devoted product manager by day, but come evening, I'm the force behind a Gen-AI Tool - tulsk.io. My mission? To fuel your venture, guide you through the startup world, spotlighting user experience, product management, and growth strategies. Keen to dive deeper? Join the tulsk.io community. Your support is invaluable and ensures I can share insights for budding entrepreneurs like you. Let's journey together!

Large Language Models (LLMs) have been a significant breakthrough in natural language processing, enhancing our capabilities in text understanding, generation, and reasoning. However, they also tend to produce hallucinations — content that is inconsistent with real-world facts or user inputs, posing challenges for their practical deployment.
The term 'AI hallucinations' refers to the inaccuracies or false information that language models sometimes generate. Techniques such as ToT prompting, grounding the model, self-consistency, instruction tuning, and least-to-most prompting can mitigate, but not fully eliminate these hallucinations. Researchers, including Yann LeCun, believe that preventing models from hallucinating is a complex challenge, due to the nature of auto-regressive generative models.
Addressing this challenge, a new, comprehensive paper has been published in which researchers present a novel approach to classifying hallucinations in Large Language Models (LLMs). Furthermore, it examines a spectrum of strategies aimed at reducing the occurrence of hallucinations. The title of the paper is "A Survey on Hallucination in LLMs: Principles, Taxonomy, Challenges, and Open Questions."
Reflecting on this paper, here are some questions you might be curious about
How are hallucinations in LLMs categorized?
What causes hallucinations in LLMs?
How do LLMs capture factual knowledge?
What are the challenges in LLM knowledge recall?
What resources are available for understanding and detecting AI hallucinations?
What are some new techniques for mitigating AI hallucinations?
How are hallucinations in LLMs categorized?
It can be categorized into two main groups: factuality hallucination and faithfulness hallucination.

Factuality Hallucination: This category emphasizes discrepancies between the generated content and verifiable real-world facts. It typically manifests as factual inconsistency or fabrication. This type of hallucination is concerned with the accuracy of the information provided by the LLM.
Faithfulness Hallucination: It occurs when the generated content either lacks contextual consistency, does not align with the provided input, or misaligns with user intent, diverging from what the user actually asked for or intended.
What causes hallucinations in LLMs?
Hallucinations in Large Language Models (LLMs) originate from a mix of factors related to data quality, training methodologies, and the inference process:
Flawed Data Sources: When training data contains incorrect, outdated, or biased information, LLMs tend to replicate these errors in their outputs.
Ineffective Utilization of Factual Knowledge: LLMs may produce hallucinations if they improperly use factual knowledge, which can occur due to challenges in identifying relevant information or overly relying on superficial data correlations.
Inferior Training Strategies: If training approaches fail to adequately address the complexities of language understanding or contextual relevance, it can lead to hallucinations.
These factors lead to inaccuracies in the model’s outputs, contributing to the redefined taxonomy of hallucination in LLMs as below

How do LLMs capture factual knowledge?
Despite significant research into how Large Language Models (LLMs) store and probe knowledge, the exact method they use to capture factual information remains unclear.
Studies suggest that LLMs often rely on shortcuts, such as using co-occurrence statistics and positional closeness in their training data, which can lead to biases and factual inaccuracies. For example, an LLM might incorrectly identify "Toronto" as the capital of Canada due to Toronto's frequent association with Canada in the training data, rather than accurately recognizing Ottawa as the capital.
What are the challenges in LLM knowledge recall?

The research presented in “Large Language Models Struggle to Learn Long-Tail Knowledge“ highlights several challenges that Large Language Models (LLMs) encounter, particularly in recalling long-tail knowledge and dealing with complex scenarios that require multi-hop reasoning. These difficulties often lead to instances of hallucination, where LLMs, despite their vast knowledge bases, struggle to apply this information effectively. Key aspects of these challenges include:
Difficulty in Learning Long-Tail Knowledge: LLMs often struggle to learn and recall information that is rare or infrequently encountered.
Influence of Data Frequency on Recall Accuracy: The accuracy with which LLMs recall information is closely tied to how frequently that information appears in their pre-training datasets.
Performance of Larger Models with Rare Knowledge: While larger LLMs show a better aptitude for learning long-tail knowledge, scaling them to effectively handle rare knowledge remains a significant challenge.
Effect of Relevant Document Count on LLM Performance: The number of relevant documents present in an LLM’s pre-training data is directly related to its accuracy in answering questions, particularly those concerning less common topics.
Limited Impact of Scaling Pre-training Data: Merely increasing the volume of pre-training data does not significantly enhance LLMs’ performance in managing long-tail knowledge, indicating the need for more nuanced training and data handling strategies.
What resources are available for understanding and detecting AI hallucinations?
Recommended Papers for Understanding AI Hallucinations:
Tools for Measuring and Detecting Hallucinations in Language Models:
Hallucination Evaluation Model (HEM): An open-source hallucination evaluation model that uses it to compare hallucination rates across top LLMs including OpenAI, Cohere, PaLM, Anthropic’s Claude 2, and more.
awesome-hallucination-detection: a comprehensive resource featuring cutting-edge papers and summaries on enhancing the reliability of language models.
Factool: a tool augmented framework for detecting factual errors of texts generated by large language models (e.g., ChatGPT). Factool now supports 4 tasks:
knowledge-based QA: Factool detects factual errors in knowledge-based QA.
code generation: Factool detects execution errors in code generation.
mathematical reasoning: Factool detects calculation errors in mathematical reasoning.
scientific literature review: Factool detects hallucinated scientific literature.
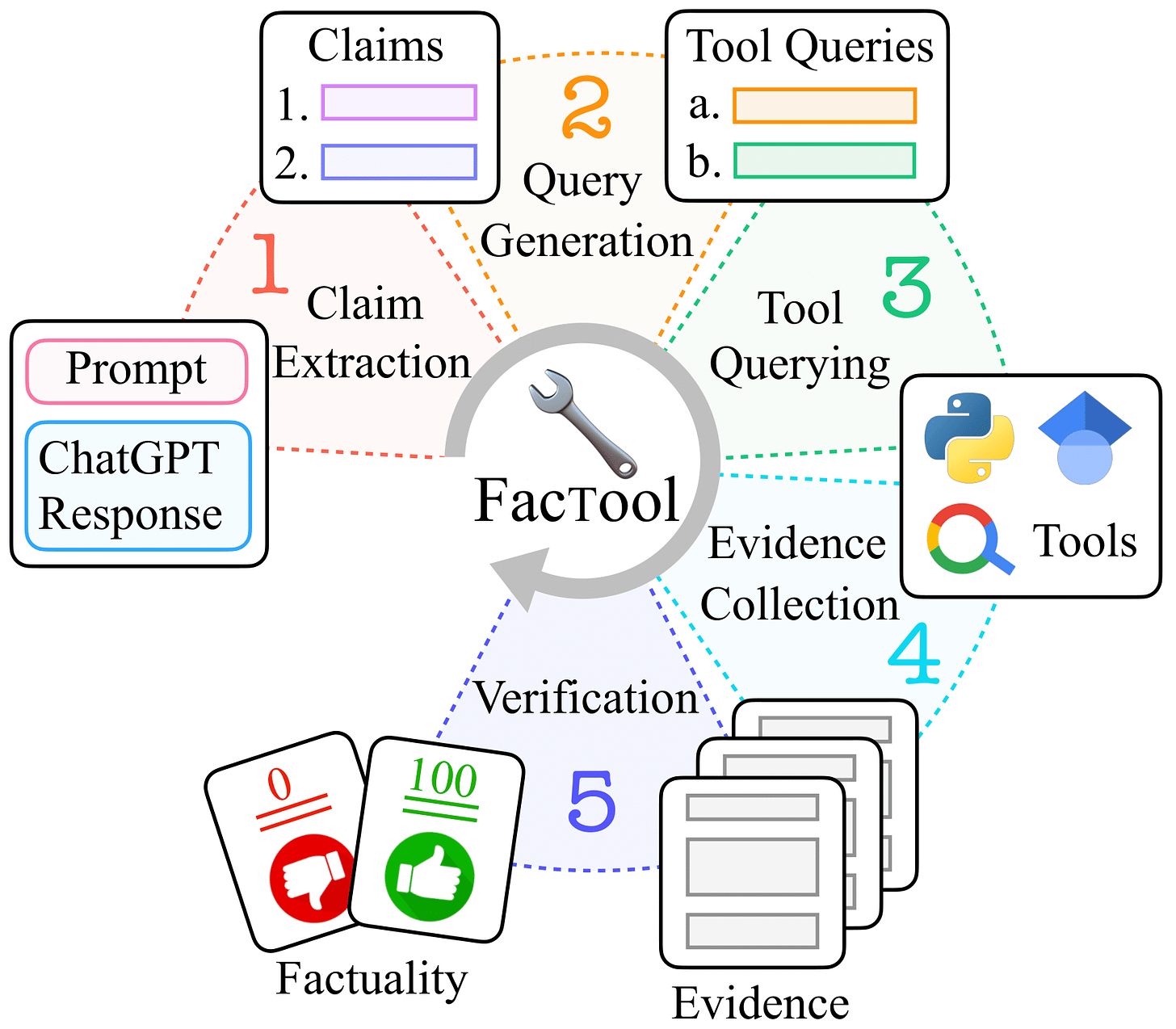
https://github.com/GAIR-NLP/factool


What are some new techniques for mitigating AI hallucinations?
New techniques include:
Chain of Verification (CoVe): A method that uses a response generated by a language model to validate itself.
Forward-looking Active RAG (FLARE): This method anticipates future content to minimize hallucinations.
CoBa (Correction with Backtracking): Developed by Deepmind & Cornell University, this method detects and mitigates hallucinations in abstractive summarization.
SynTra: A method that uses synthetic tasks to teach language models to hallucinate less.
Conclusion
Large Language Models (LLMs) excel in language processing but struggle with 'AI hallucinations' - false information diverging from reality. The paper "A Survey on Hallucination in LLMs" categorizes these hallucinations, examines their causes like flawed data and ineffective training, and discusses mitigation strategies. Tools like HEM and Factool, along with new techniques like CoVe and FLARE, are highlighted for addressing these challenges in LLMs.
Related Paper
Overview of Related Research and Methods in Language Model Development
Chain of Verification (CoVe): A method that uses a response generated by a language model to validate itself.
Forward-looking Active RAG (FLARE): This method anticipates future content to minimize hallucinations.
CoBa (Correction with Backtracking): Developed by Deepmind & Cornell University, this method detects and mitigates hallucinations in abstractive summarization.
SynTra: A method that uses synthetic tasks to teach language models to hallucinate less.
Exploring Knowledge Storage:
Geva et al., 2021: Investigated the methods LLMs use to store knowledge acquired during training.
Probing LLMs for Knowledge Retrieval:
Petroni et al., 2019: Examined how LLMs retrieve stored knowledge in response to queries.
Zhong et al., 2021: Analyzed the efficiency and accuracy of knowledge retrieval by LLMs.
Yu et al., 2023c: Studied the effectiveness of LLMs in accessing and utilizing their stored knowledge.
Research Indicating Reliance on Shortcuts for Knowledge Capture:
Li et al., 2022a: Found that LLMs tend to depend on positional closeness in training data.
Kang and Choi, 2023: Demonstrated LLMs’ over-reliance on co-occurrence statistics.
Kandpal et al., 2023: Highlighted the bias towards document count in LLMs' training data leading to potential factual inaccuracies.
🌟 Spread the Curiosity! 🌟
Enjoyed "Curiosity Ashes"? Help ignite a wave of innovation and discovery by sharing this publication with your network. Let's foster a community where knowledge is celebrated and shared. Hit the share button now!