


A Primer on Vector Databases
I’ll explain how it works, why it’s useful, and what to consider.

Unstructured data is everywhere. According to Gartner, it makes up 80 to 90 percent of all new enterprise data and is growing three times faster than structured data. ITC predicts that unstructured data will grow from 33 zettabytes in 2018 to 175 zettabytes by 2025 – that’s 175 billion terabytes!

The development of vector databases began in the early 2000s at the University of California, Berkeley, where researchers sought to create a database specifically designed for storing and querying high-dimensional vectors. These databases have since evolved to help structure and manage vast amounts of unstructured data effectively.
In the next section, I’ll explain how vector databases can help manage this massive amount of data.
Why Vector databases Works?
Traditional SQL databases are designed for structured data, which can be limiting when dealing with complex, unstructured data like user interactions, preferences, and behaviors. These databases require complex joins and queries to understand relationships between different data points, making them inefficient and slow.
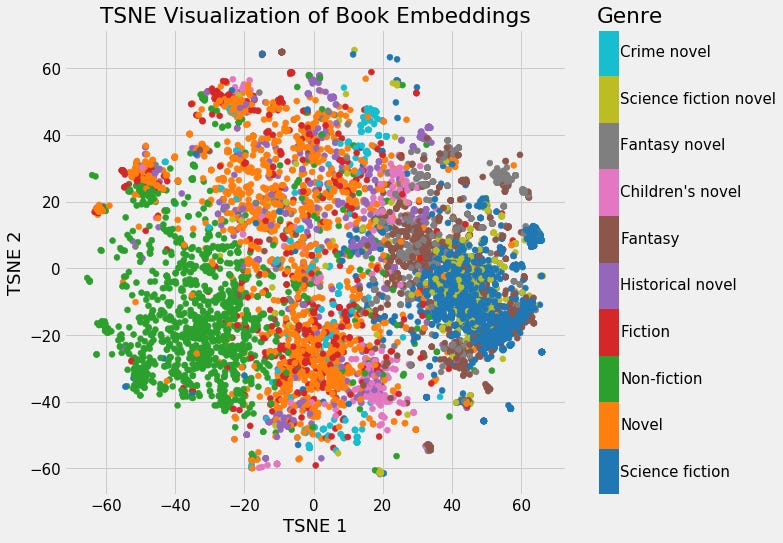
Vector databases, a newer entry in the database technology landscape, are designed to handle high-dimensional vector storage. In these databases, data is represented as vectors in a multidimensional space, optimized for efficient similarity searches. This makes vector databases particularly suitable for machine learning, AI, and real-time analytics applications.
One key technology enabling the effectiveness of vector databases is embeddings.
Embeddings turn words into numbers while keeping their meanings. Neural networks create these embeddings by looking at many examples. Similar words get similar embeddings, which helps computers understand language better.
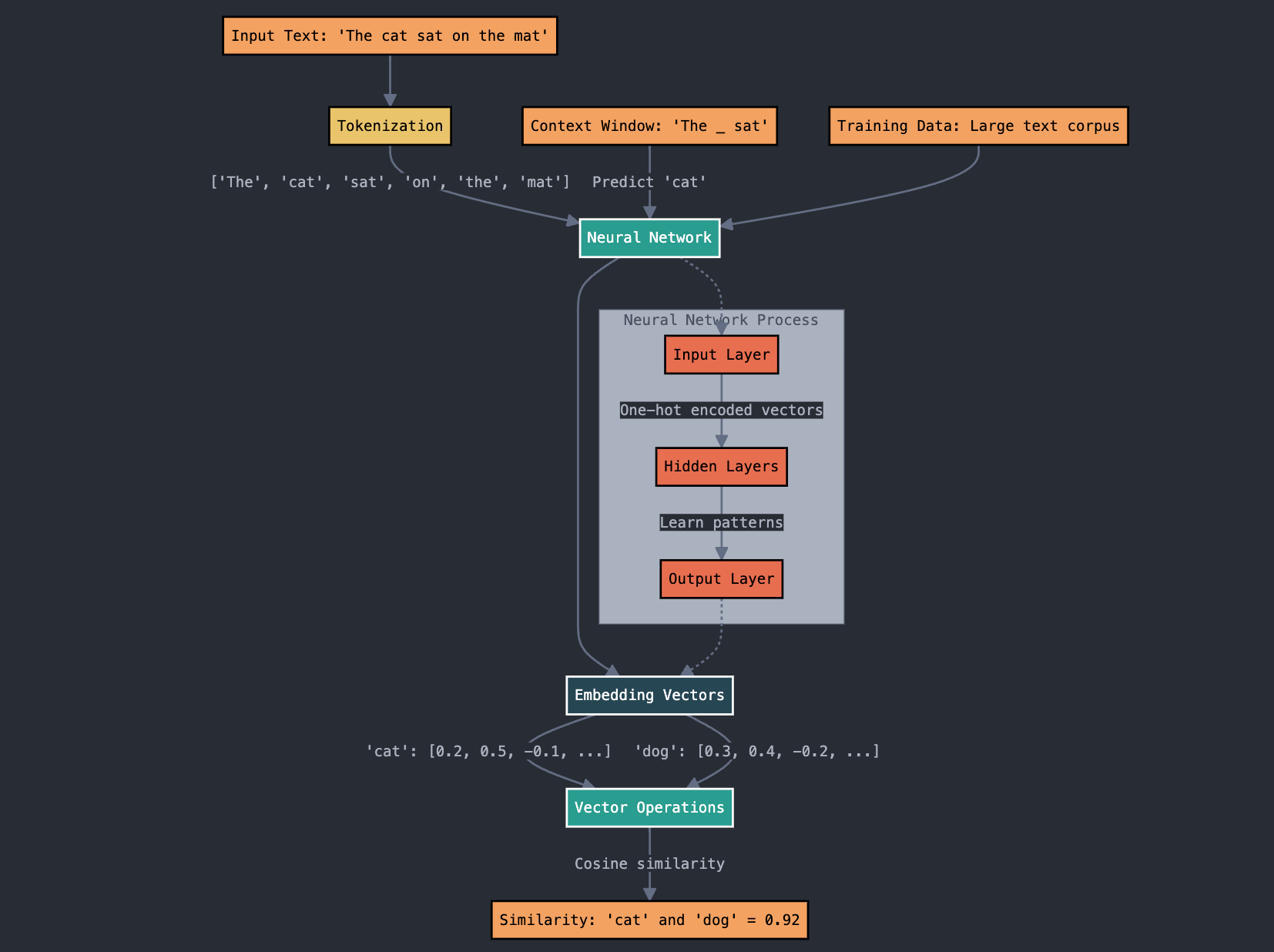
We use embeddings to measure how related words are or for different language tasks. For example, we can find the similarity between two words or documents using vector cosine similarity. This means calculating the cosine of the angle between two vectors; a higher cosine value means more similarity.

In short, vectors in NLP are mathematical representations of words or documents used for tasks like sentiment analysis, text classification, and information retrieval.
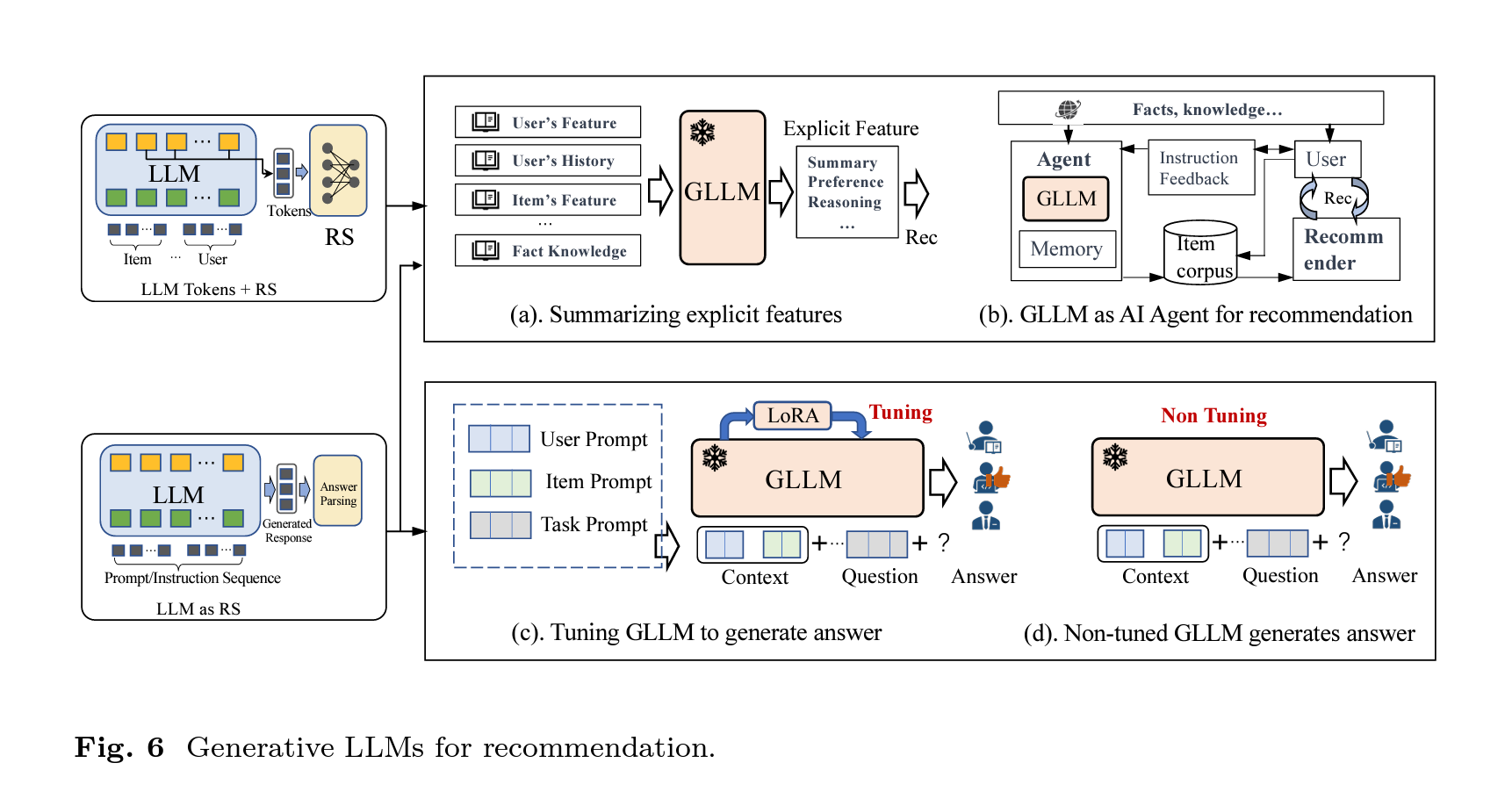
Given the concept of cosine similarity, recommendation systems are a great use case for vector databases with LLMs. For instance, a 2023 paper highlighted the use of different modeling methods to innovate recommendation systems, leveraging the power of vector databases to enhance their accuracy and efficiency.
Vector-Based Recommendation Systems Solve the Cold Start Problem
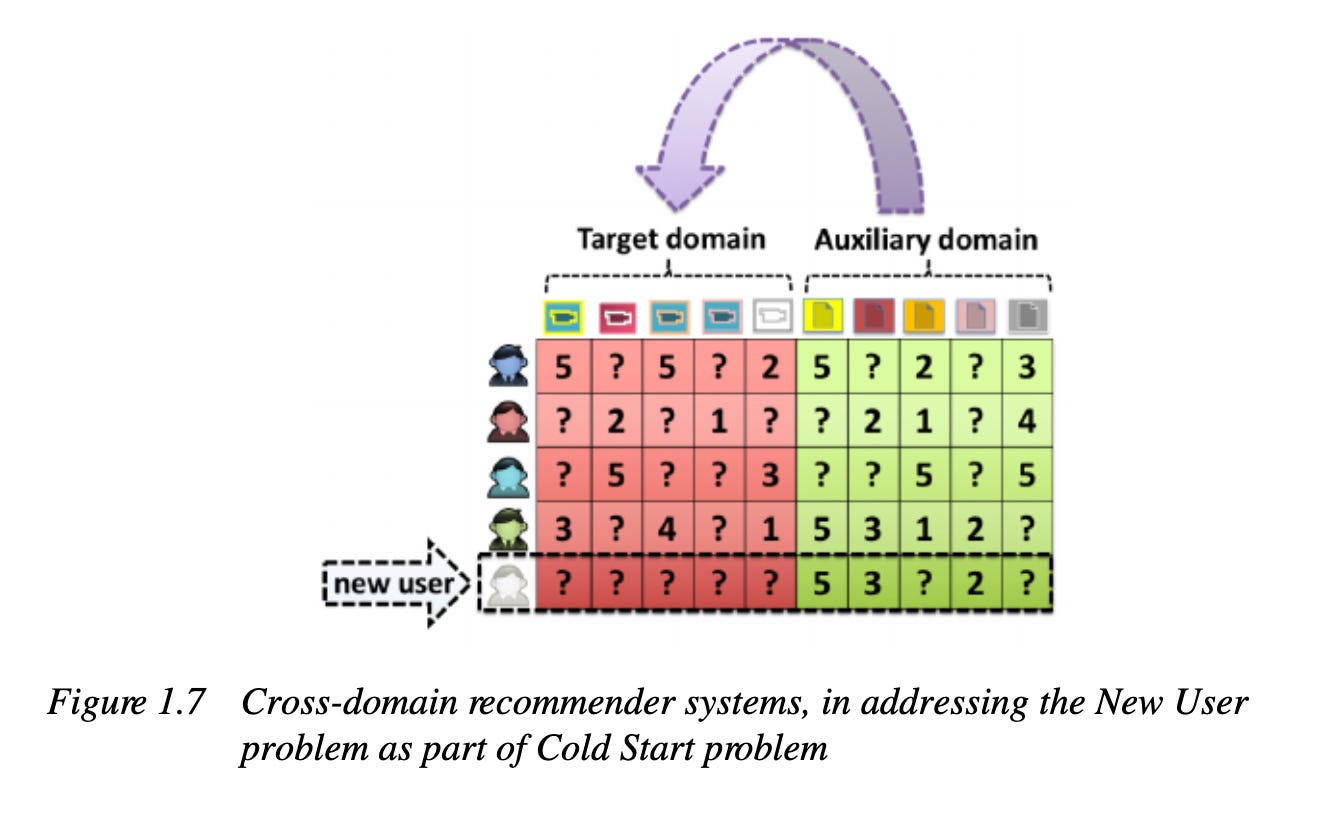
So, how can vector databases improve user experiences, particularly in recommendation systems?
Imagine you join a new music streaming service. The service wants to recommend songs you’ll love but doesn’t know your taste yet. This is the “cold start problem” in recommender systems, occurring in two scenarios:
New User Cold Start: No data on a new user’s preferences.
New Item Cold Start: No information on which users might like a new song.
Vector databases address this by:
Semantic Embedding: Representing items as vectors based on attributes.
User Embedding: Encoding user preferences as vectors.
Similarity Search: Quickly finding similar items for new users.
Cold Start Mitigation: Recommending new items to users who liked similar ones.
Cross-Domain Transfer: Using vectors from one domain (e.g., books) to initialize another (e.g., movies).
By using vector representations and efficient similarity searches, vector databases help recommender systems predict preferences with limited data, solving the cold start problem.
Relational Database vs. Vector Database
While vector databases are beneficial, it’s important to understand the attributes of each database type to know what kind of data to store and when to use the suitable database. Here’s a comparison:
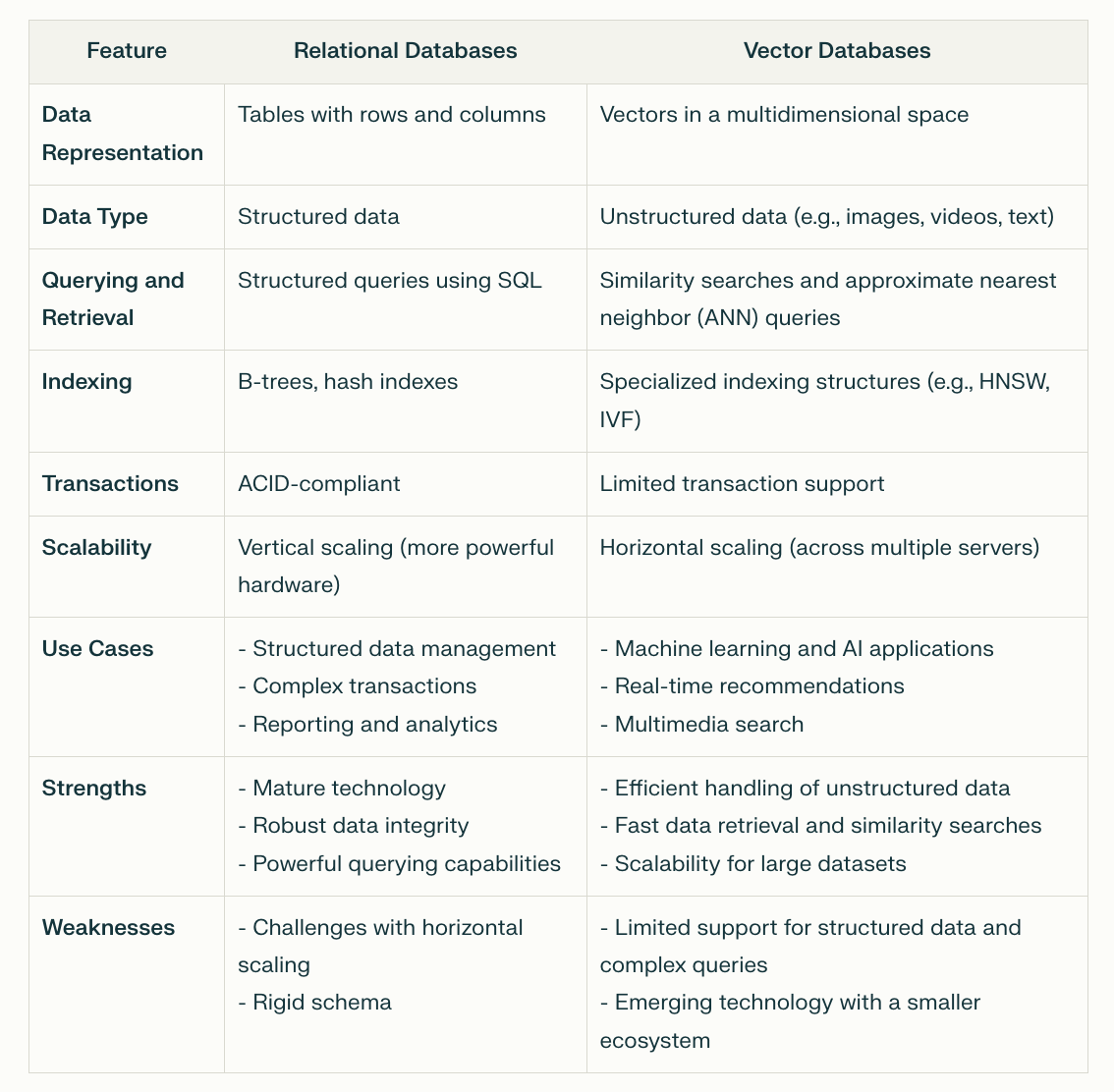
Relational Databases:
Handle structured data with well-defined relationships
Support complex transactions and ACID compliance
Model tabular data using rows and columns
Query data using structured SQL
Vector Databases:
Handle unstructured and complex data like images, videos, text, and audio
Process and retrieve data based on similarity in a high-dimensional space
Suitable for machine learning, AI, and real-time analytics
Efficiently search and retrieve data without well-defined relationships
Thoughts
To be realistic, a software company should consider using both types of database architectures for different purposes. While the technology behind databases is exciting, it’s crucial to evaluate them thoroughly to make the most suitable decision. Here are some questions to consider:
How can your organization prepare for the future of AI in software development?
What are the limitations of traditional and vector databases?
How do I transition from a traditional database to a vector database?
Are your vector databases setup ready for production use?
I hope these questions help guide your research and evaluation of new database solutions to fit your needs.
Hi, I'm Kevin Wang!
By day, I'm a product manager diving into the latest tech innovations. In my free time, I'm the creator behind tulsk.io, a platform dedicated to PM Intelligence. My passion? Breaking down the complexities of web3 and AI into bite-sized, understandable concepts.
My goal is simple: to make cutting-edge technologies accessible to everyone. Whether you're looking to expand your knowledge or apply these insights to your personal growth, I'm here to guide you through the exciting worlds of web3 and AI.
Why Choose Curiosity Insights?
We offer:
Cutting-edge Analysis: Our team of experts dissects the latest developments in AI and Web3, providing you with actionable insights.
Strategic Advantage: Stay ahead of the curve and make informed decisions that drive innovation and growth.
Comprehensive Coverage: From investment opportunities to technological breakthroughs, we've got you covered.
Upgrade to Premium and Unleash the Power of Knowledge
Our Premium newsletter delivers:
Weekly In-Depth Research: Dive deep into AI and Web3 trends, curated and analyzed by industry experts.
Exclusive Expert Access: Gain valuable insights from thought leaders shaping the future of technology.
Full Archive Access: Explore our extensive knowledge base to identify emerging trends and technologies.